Concept and Vision
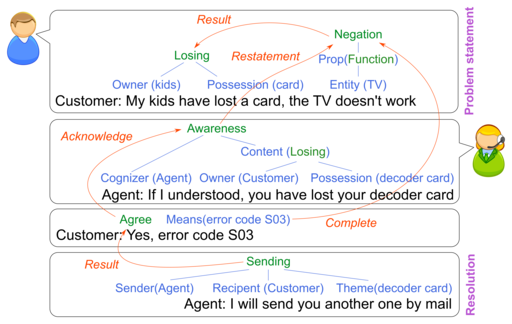
The goal of the DATCHA project is to perform knowledge extraction from very large databases of WEB chat conversations between operators and clients in customer contact centers (technical and commercial).
Multichannel capability is a key component of today's Customer Relationship Management (CRM). If traditional telephone call-centers remain central in customer interactions with a company, the proportion of inputs from other channels (web, mail, social media...) is constantly growing. Among these new interaction patterns, chat is becoming more and more popular. It has the advantage of remaining a synchronous interaction mode while offering interesting properties: for customers who are proposed a live interaction at an appropriate moment (pro-active chat or ClickToChat), for agents who generally prefer synchronous interactions and who report that the distance induced by written interaction reduces conflicts and aggressive behavior, and for companies who can reduce their contact center costs while gathering via direct interaction with customers rich and varied information concerning "real" problems or issues of concern.
Accessing this rich knowledge however is a challenging research issue. Simply applying traditional text mining tools is clearly sub-optimal as it takes into account neither the interactive dimension nor the particular nature of this language which shares properties with both spoken and written language. While most research on synchronous contact center data has been carried out on telephone interactions, this project would represent a great opportunity to study a new type of interaction that has potential impact on many other fields beyond CRM. Unlike research on spoken conversations where manual transcriptions are always problematic, the availability of very large corpora collected on a daily basis is guaranteed for this project, thus offering opportunities for engaging research on relevant unsupervised analysis approaches.
From a societal point of view the DATCHA project is an opportunity to better understand the way people use these new interactive interfaces that are present in all WEB-related social media. WEB chat conversations represent massive corpora of such interactive data that can be mined to extract such knowledge.
The DATCHA project will address scientific issues including intra-conversation analysis through a deep semantic analysis (syntactic, semantic, discursive and structural analysis) and inter-conversation analysis (definition of semantic and discursive similarity between conversations). It will propose innovative solutions in various use- cases including analytics report generation, automatic synthesis generation of a (potentially dynamic) set of conversations, conversation success prediction on the basis of criteria defined by operational units, and online conversation solving.
For more information, please read the scientific document of the project.
Last updated on 2018-08-08